 DomCop
DomCopForget starting your website authority from zero. For serious SEOs and domain investors, the fastest route to success is securing a high-quality expired domain. These domains already have powerful backlinks, giving you an instant, massive SEO boost. Traditional domain lists are fine, but the real advantage is finding the domains nobody else has touched.
Enter DomCop’s Personal Expired Domain Crawler. Exclusive to the Guru Plan, this powerful feature is your secret weapon. Launched in 2016, it offers a proven method for expired domain mining, delivering hundreds of high-authority domains exclusively for your use.
DomCop Expired Domain Crawler Overview
The crawler works differently from the way the DomCop expires lists work. Instead of finding expired domains and seeing if they have great back links, the crawler finds great broken back links and finds if the domain is available.
That is, the crawler crawls websites on your behalf and looks for any broken links from those websites. If a broken link is found, it then checks whether the domain is available. If a domain is found to be available, it then gets all the metrics for the domain that we normally have at DomCop (Majestic, Moz, SimilarWeb, SEMrush, Alexa etc). This is also called expired domains mining.
Every domain that the crawler finds for you, is only available to you. Your list of domains is not shared with any other user.
We have rolled out the guru plan under three sub plans
- Guru Plan I – $184/mo – Gives you 10 crawlers
- Guru Plan II – $372/mo – Gives you 30 crawlers
- Guru Plan III – $556/mo – Gives you 50 crawlers
Each sub plan give you a fixed number of crawlers. For example, the Guru Plan III gives you 50 crawlers – this means that at any time, 50 crawlers will be working on 50 different websites for you. There are no limitations on the number of jobs you can setup, or the number of websites you can crawl.
Crawler Dashboard
When you sign up for the Guru plan, you will see a new link at the top called “Crawler Dashboard“. When you visit the link you will see a screen like the screenshot below
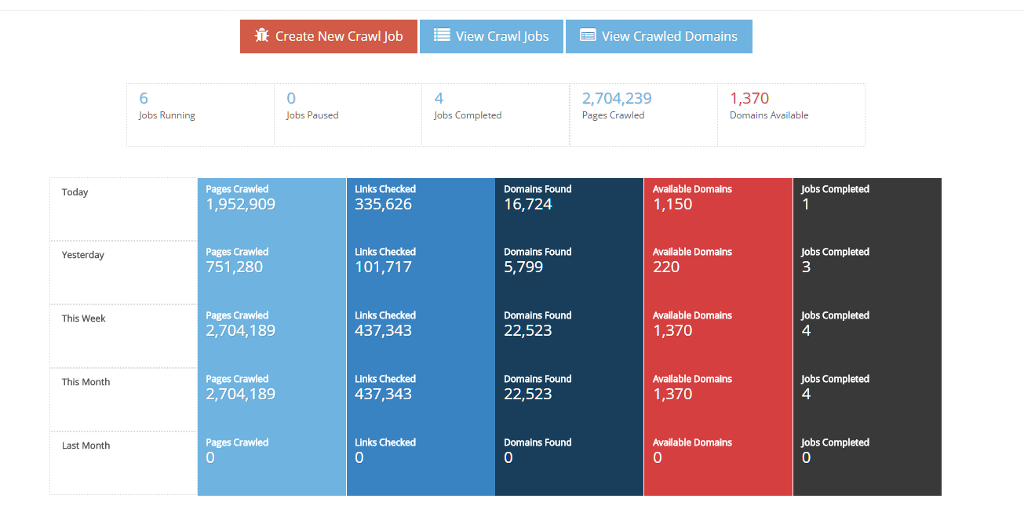
Well, on your first login, this screen will be empty. But as your personal crawler crawls websites and finds domains, you will be able to see the stats on how it is doing on this page.
Creating a new crawl job
To create a new crawl job, click on the “Create new crawl job” button. This will take you to a page where you can choose the type of crawl job you would like to create. I am listing the different types of crawl jobs below. I will explain them in more detail later on in the article.
- Website Crawl – this is the default crawl job, where you can enter a bunch of websites (up to 500) and have the personal crawler crawl all of them for you.
- Keyword Search – with this type of job you can crawl all those websites that are found in the Google search engine results for specific keywords. You can enter up to 20 keywords at once.
- Reverse Website – using this job, you can crawl all those websites that link to a single or a set of websites. This is a great place to enter your competitor websites (or websites in a similar niche). You can enter up to 50 competitor websites at once.
- Niche Website – this is the easiest job to setup. Simply choose your niche from the list shown and the crawler will pick up random websites from your niche.
Choosing settings for each crawl job
Let’s go in details to understand the various settings in each crawl job.
Website Crawl
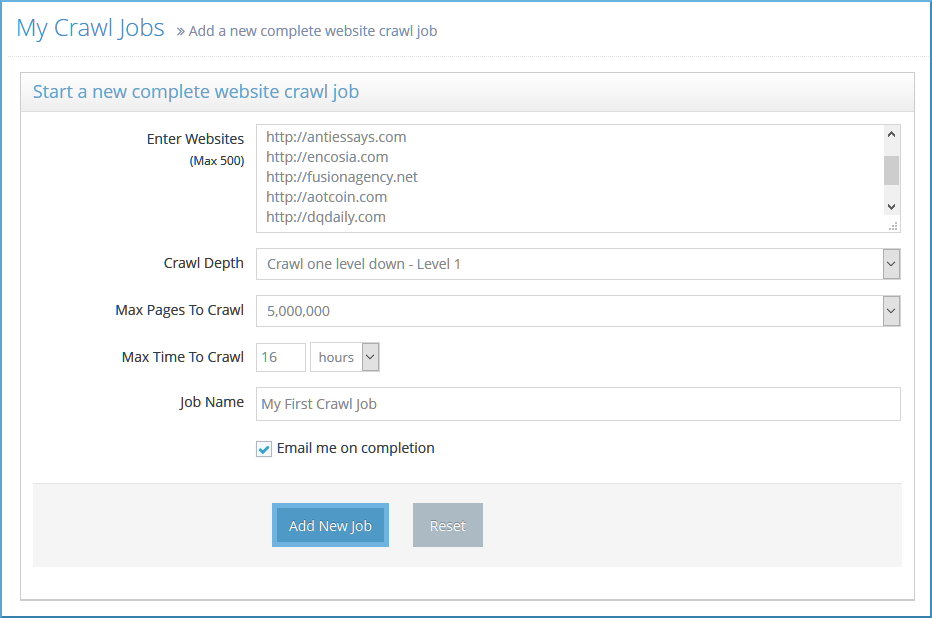
Enter Websites: As you can see, I’ve added some random websites with Alexa Rank > 50,000. You can choose websites from any such list – Top Alexa, Top Majestic or you can add any other website that you want to crawl.
Crawl Depth: This is the depth to which the website shall be crawled. A higher depth means more pages crawled, but it also means that the crawler takes a long time to complete. You should test with different depths to see what works for you. If you are unsure, go with the default Level 3.
Max Pages to Crawl: If you want the crawler to stop after it has crawled a certain number of pages, you can choose that from here. As you can see I’ve kept this to a max of 5 million pages.
Max Time to Crawl: This is similar to the above setting. It decides how long you want the crawler to run. If I have a large list of jobs setup, I can force this job to end within 16 hours after it starts.
Job Name (optional): Enter a relevant job name if you want. If you leave this empty, a default format name will be applied
Email on completion (optional): If you want to be notified via email when the job is complete, you can enable this checkbox.
Keyword Search Crawl
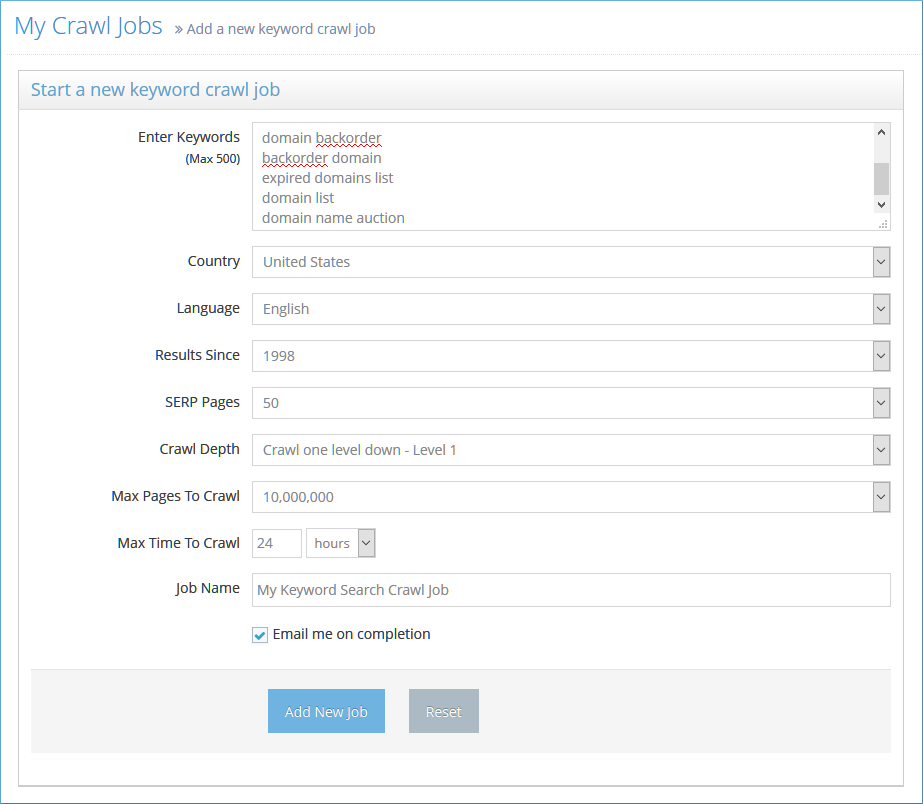
The keyword search crawler performs searches on Google and gets the top 10/20 results. It then crawls these results.
Enter Keywords: You can enter up to 20 keywords from your niche here.
Country: Choose the country you want the Google search to be done in. Default – US.
Language: Choose the language that you want the Google searches to be performed in. Default – English.
Results Since: If you want to include older search results, choose the year.
SERP Pages: You can choose whether you want the top 20, 50 or 100 results from Google to be crawled.
If you enter 20 keywords and select 20 results from the SERPs you can actually get 20 x 20 = 400 websites from this crawl job.
Reverse Website Crawl Job
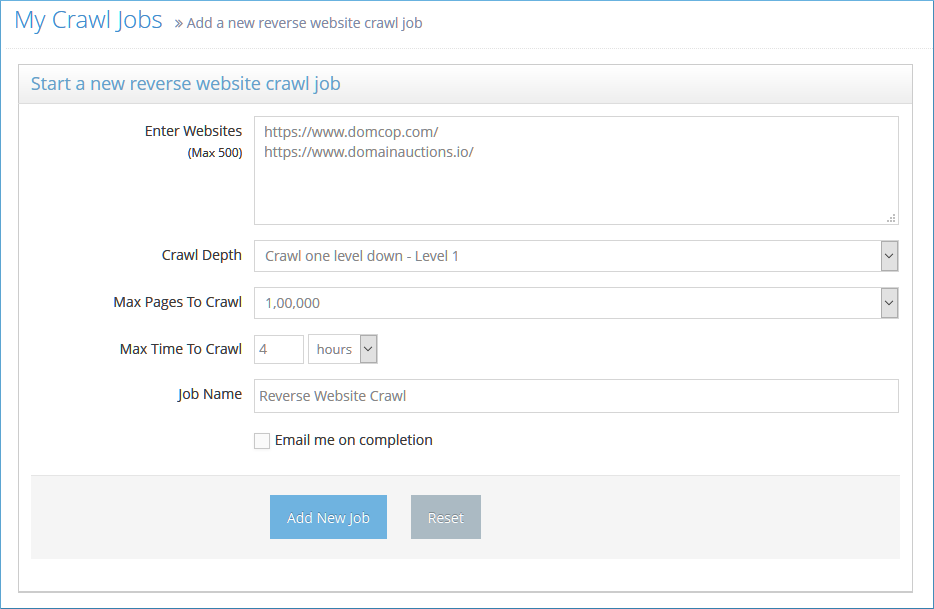
Enter Websites: Enter high ranking competitor websites. The crawler will use the SemRush API to get the top 50 backlinks to each of these websites and will crawl those websites. You can enter a maximum of 50 websites here. If each of those has at least 50 backlinks, you will have a total of 50 x 50 = 250 websites to crawl.
Niche Website Crawl Job
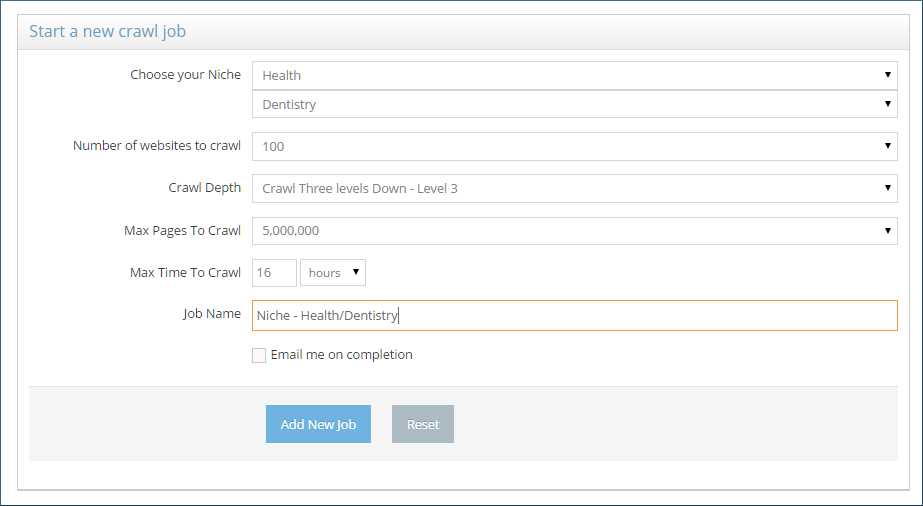
Choose your Niche: You can choose the parent and the child category of your niche.
Number of websites to crawl: here you can choose how many niche sites the crawler will crawl for this job
The crawler will randomly pick up websites that fall in your specific niche and start crawling the number of websites that you setup.
Viewing all the domains found and search/sorting by metrics
Your crawled domains are perfectly integrated into the DomCop domain grid. If you have used DomCop before, you will not have any issues with this section.
Your crawled domains show up in a new tab called “Crawler” next to the “Watchlist” tab.
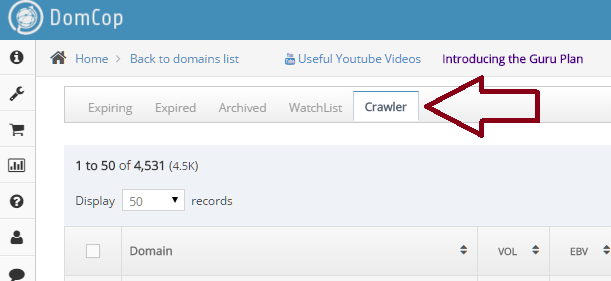
You can search and sort these domains in exactly the same way as you would sort and search through any of the other sections (Expiring, Expired, Archive or Watchlist). You have access to the Simple and Advanced search screens as well as all the metrics.
You can also filter domains on the type of crawl jobs that they were found through or the status of the crawl jobs. So, you can look for all domains that were found through completed keyword search crawl jobs.
You can also filter domains based on a specific crawl job or a specific website inside a crawl job.

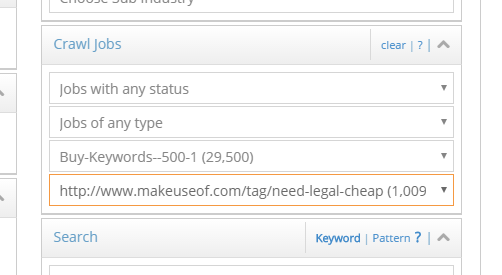
The domains in the crawler tab are only shown to you. This is your private list of domains.
Miscellaneous Settings
Show Domains – we find domains with all extensions in our crawls. However, due to the limitation with availability check APIs, we cannot check the availability of all the domains. By default, we do not show these domains to you. However, since these domains might be available, you can choose to see them in the domain list by changing the setting “Crawled Domain Setting” on the My Account page.
Expert Tips for Max Crawl Success
To maximize your return and achieve results like finding 175 TF10+ domains in a single day, follow these expert tips:
- Avoid Famous Websites: Do not waste resources on highly popular sites like huffingtonpost.com. Everyone regularly crawls these, and any good domains have already been picked up.
- Focus on Your Niche: Concentrate your efforts on high-authority websites that are specific to your niche. Competition for these niche-relevant broken links is lower, dramatically increasing your chance of finding a valuable, relevant domain.
- Batch Your Jobs: Since you get a fixed number of crawlers (10 on Guru Plan I), and each crawler handles one website at a time, it’s efficient to have at least 10 websites in every job (or run multiple jobs simultaneously) to keep all your crawlers working.
- Be Patient: Expired domain mining is a numbers game. Based on internal stats, you generally need to crawl around 2,000 pages to find a single available domain. Set up your jobs, and give the crawler the time and space it needs to process the immense volume of data.
Conclusion
The DomCop Personal Expired Domain Crawler is the ultimate tool for serious domain investors and SEO professionals. By focusing on proven broken backlinks, it completely bypasses the competition for common lists and delivers a valuable inventory of available domains. This advanced mining technique, combined with DomCop’s metrics, streamlines your search for premium domains.
You can go ahead and purchase the Guru Plan right away!
For any questions, please email the support team at support@domcop.com.
Happy Crawling!
Expired Domain Crawler FAQs
What is the core difference between the Crawler and DomCop’s regular expired domain lists?
Regular lists check domains that are expiring or expired and then check their metrics. The Crawler checks active websites for broken links, and if a broken link points to a domain that is available to register, it adds it to your private list. It finds domains that are not yet on any public drop list.
Does the Crawler identify domains that are guaranteed to be high-quality?
The domains are guaranteed to have a live backlink from the website you crawled, and they come with all of DomCop’s comprehensive metrics (Majestic, Moz, etc.). You must use the integrated search and filtering tools to set your desired quality thresholds (e.g., minimum TF, DA, or CF).
Is there a limit to how many domains the Crawler can find?
No, there is no limit to the number of domains your personal crawler can find and add to your list. The only limitation is the number of concurrent websites your dedicated crawlers (10, 30, or 50) can process at any one time.
How long should a crawl run?
It varies based on the number of pages and crawl depth. You can set time limits manually or let the crawler finish automatically.
How current is the data on the backlinking websites?
The data is current as of the moment the crawler processes the website. It is actively checking for broken links in real-time as the job runs.
Why shouldn’t I crawl huge, famous sites?
Famous sites like major news outlets have already been repeatedly crawled by thousands of users over the years. Your time and crawler power are better spent on niche-specific, high-authority sites where the competition for unique broken links is significantly lower.
Will other users see the domains my crawler finds?
No. Every domain your crawler discovers is 100% private to your account.